
Article context: Azure Search Service that indexes a document and provides features like Synonyms, Spelling Corrections and Facets. Azure Search Service stores the data in the form of documents (in JSON format) and will manages multiple indexes to retrieve data in faster mode. Azure Search will create inverted index for full text searches to search texts in the documents easily.
“Inverted Index” is an index into a set of texts in a sentence (document content) that is spawned across many documents. This index will be used by search analyzers or readers of the search engine. Each index will be holding each word or text and references to the word in different documents.
This can be thought of as index of the words at the end of book. If someone wants to look at the references of one word, then index at the end of the book provides references to the word in all the pages wherever it was present. This helps the reader to easily find the location of a word in all the pages and can concentrate only on those pages to read the relevant content related to the word. For example, if a book has a word “Photosynthesis” on page 45, 67, 89 and 95 then the index of this word will be added in the book at the end as below:
P
Photosynthesis…45,67,89,95

For this article, we would be assuming two documents that are to be indexed.
Document 1 content:
The Indian subcontinent or the subcontinent, is a southern region of Asia
Document 2 content:
Sometimes, the term South Asia is used interchangeably with Indian subcontinent
Steps to generate inverted index:
- Collect the documents that are to be indexed.
- Tokenize the text
- Do linguistic preprocessing, producing a list of normalized tokens, which are indexed terms.
- Index the documents for occurrence of each term with respect to document.
- Create an Inverted Index by building a list or dictionary of terms, frequency of their occurrence and document IDs for reference sorted alphabetically.
Step 1: Collect the documents to be indexed.
[The Indian subcontinent or the subcontinent, is a southern region of Asia.][Sometimes, the term South Asia is used interchangeably with Indian subcontinent.]
Step 2: Tokenize the text i.e. convert the document into tokens or individual texts.
[The][Indian][subcontinent][or][the][subcontinent][is][a][southern][region][of][Asia][Sometimes][the][term][South Asia][is][used][interchangeably] [with][Indian][subcontinent]
Step 3: Producing a list of normalized tokens.
[The][India][subcontinent][or][the][subcontinent][is][a][south][region][of][Asia][Sometime][the][term][South Asia][is][use][interchangeable] [with] [India] [subcontinent]
Step 4: Index the documents for occurrence of each term.
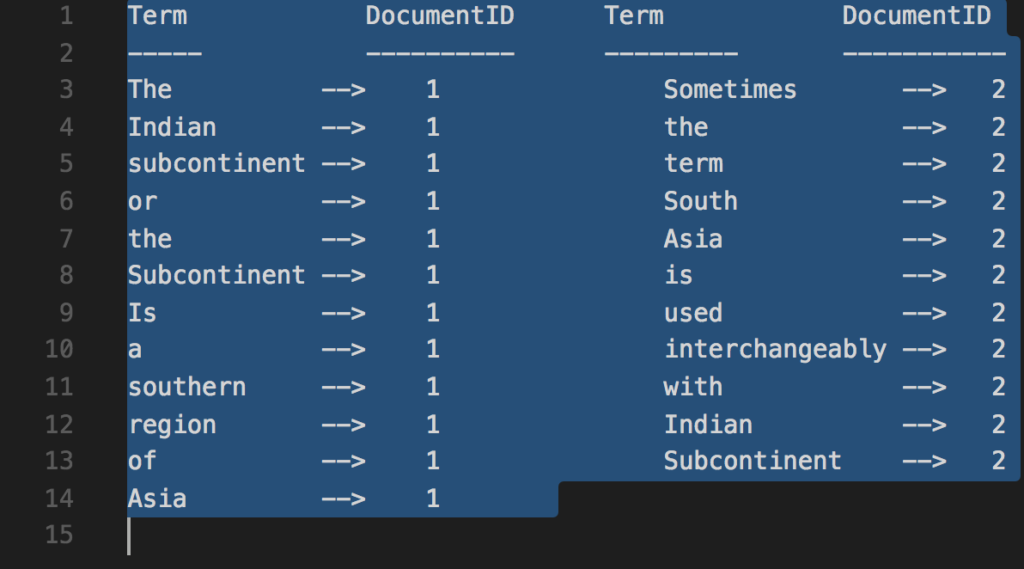
Step 5: Creating an Inverted Index.
So, now list out all the terms in alphabetical sorting order and create a matrix for DocumentID, position of the term in the document (A-Z order where A=1, B=2 and so on).
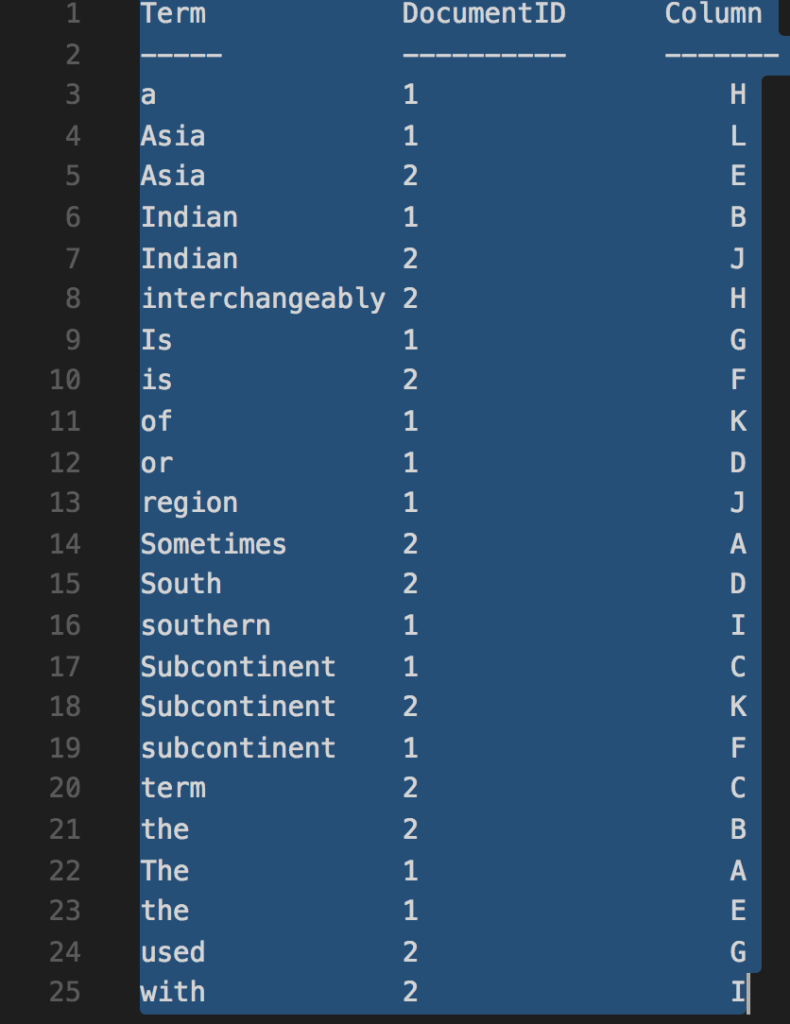
And the inverted index generated will be as below:
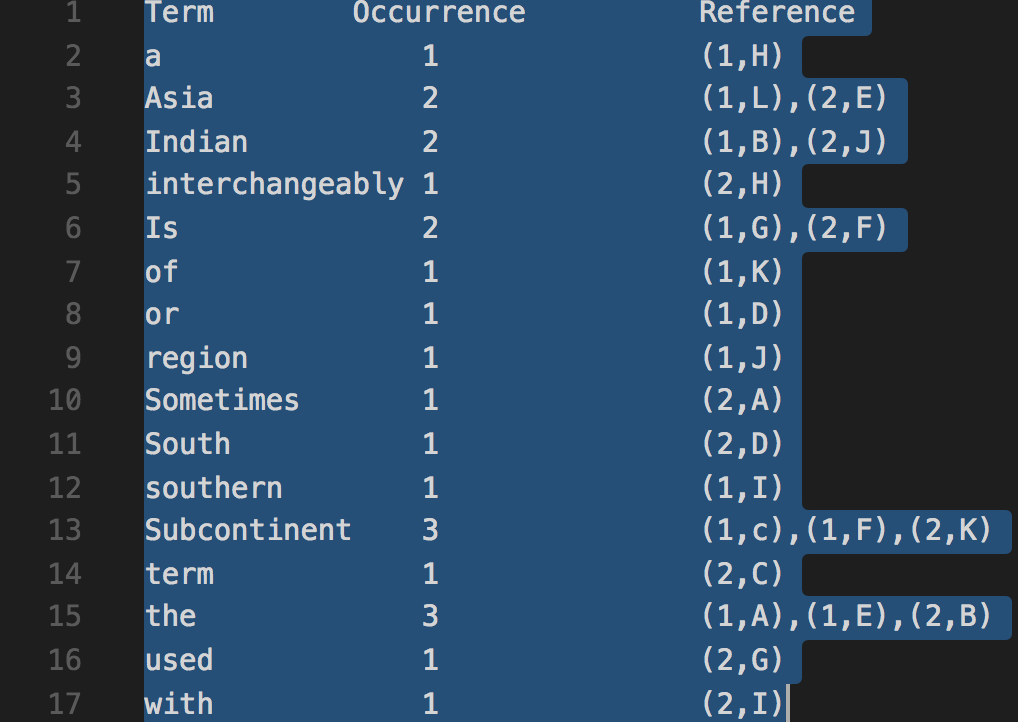
Most of the times, the search engine will be set to blacklist words like ‘a’, ‘an’, ‘the’ which will have more occurrences in a sentence and will create performance issues if they were part of the search indexes.
Using inverted index if we want to search for a string “Indian”, the search analyzer can easily point to document 1 at position B and document 2 at position J and it can retrieve results very easily. If we search for a string “used” it only searches document 2 and ignores document 1.


